Re-quantizing a local model, 14× faster
Where a 2-bit model spends its bits, and why trying answers used to cost eighty minutes

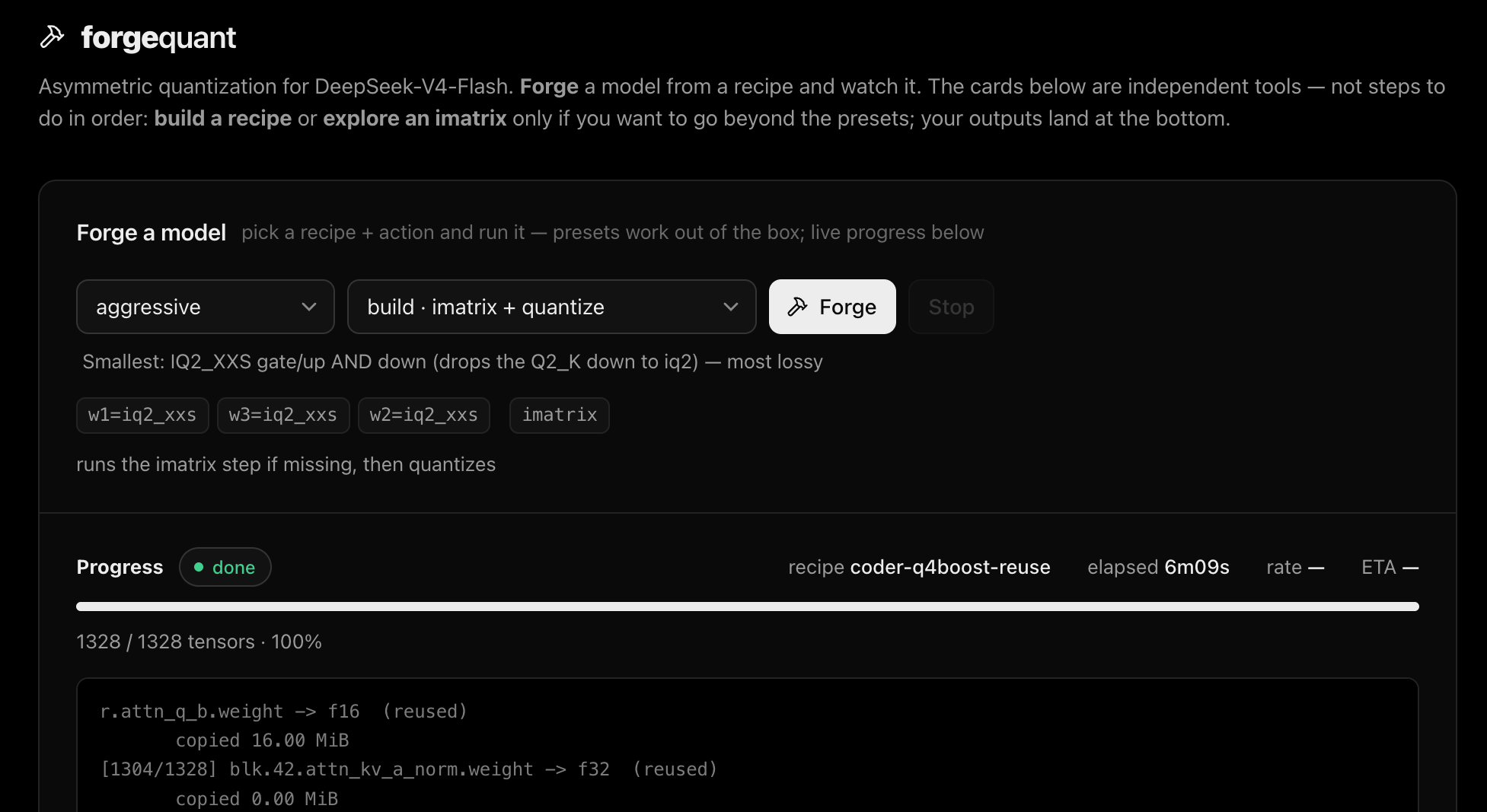
I’m writing this with DeepSeek-V4-Flash running on my Mac, on a coding build I quantized myself. It took about eighty minutes to make. The reason for this post is that I can now rebuild a tweaked version of it in five.
The quant is about 81GB, the Mac has 64GB of RAM, and it runs anyway because antirez’s ds4 streams the experts off the SSD on demand instead of holding the whole model in memory. That streaming is its own kind of magic, and it’s also why the rest of this matters: when bits cost both quality and SSD reads, you really don’t want to waste them, and the only way to learn where they’re wasted is to try.
Quick primer for anyone who hasn’t been down this hole. Models store their knowledge as numbers, normally 16 bits each. To fit one on a laptop you round those down, to 4 bits, or if you’re desperate, 2. Two bits is repainting a Caravaggio with four crayons. You can still tell what it is. It just gets noticeably dumber.
So the game isn’t “use fewer bits.” It’s “waste fewer of them.”
The part that isn’t mine
DeepSeek is a Mixture-of-Experts model: instead of one big brain it’s a crowd of small specialists (256 of them per layer, across 43 layers), and for any given word only a few wake up. That’s exactly what makes SSD streaming work. You only pull the experts you actually use. There’s also a little router that picks them, plus some always-on shared parts.
So the move is: keep the decision-makers nearly perfect (8 bits) and be brutal with the experts (2 bits). Crushing a specialist that fires occasionally costs less than fuzzing the part that’s on for every word. antirez’s ds4 already does this, and does the actual quantization. My tool, forgequant, is a thin layer on top that turns a recipe into the right ds4 commands and records what it did. Credit where it’s due: the hard part is his.
What I added comes in two parts, and I’ll start with the one I’m most sure about.
The expensive part is trying
Here’s the thing nobody tells you about “where should the bits go”: the only honest way to answer it is to build a version and measure it. And building one is slow. A full quantize of this model is about eighty minutes. So you don’t experiment. You make one educated guess, wait an hour and a half, and live with whatever you got. The bottleneck was never ideas. It was the eighty minutes.
So I went after the eighty minutes first.
The key fact is that quantization is deterministic. Same weights, same target precision, same importance matrix, and you get the exact same bytes out, every time. Which means most of a “new” build isn’t new at all. When I take a 2-bit model and promote six layers to higher precision, only those six layers change. The other thirty-seven are byte-for-byte identical to the build I already have sitting on disk. Regenerating them is pure waste.
So I added --reuse PRIOR.gguf to my fork of ds4’s quantizer. You point it at a previous build, and instead of recomputing everything it copies the tensors that didn’t change and re-quantizes only the ones that did. In my test, that turned an eighty-minute rebuild into five and a half minutes: 1,310 of the 1,328 tensors copied straight across, 18 actually regenerated.
And it’s not “close enough.” I built the same variant both ways, the slow way and with --reuse, and compared all 1,328 tensors one by one. Every single one matched, byte for byte. The fast build isn’t an approximation of the slow one. It is the slow one, assembled differently.
It’s safe by construction. Each build stamps a fingerprint of its inputs (a hash of the model index, the imatrix, and every weight shard’s size and timestamp), and --reuse only copies a tensor when that fingerprint matches and the tensor’s type and shape line up exactly. Change the imatrix, swap the weights, ask for a different precision, and the fingerprint stops matching and it quietly rebuilds the affected parts from scratch. There’s no path where it hands you a stale tensor and calls it done.
As far as I can tell this doesn’t exist anywhere else. llama.cpp always requantizes from the source weights. The closest thing in the wild is manually splicing tensors between files by hand, which is exactly what you’d want a tool to do for you.
And if you want to A/B a single change immediately, there’s an even blunter option, splice: copy the high-precision layers straight out of a donor file, no quantization at all. Seconds to minutes.
The quiet consequence is the whole point. When a rebuild costs five minutes instead of an hour and a half, you stop guessing and start searching. You build the 2-bit base once, then spin off ten variants in the time the old way made one. And because a recipe is just a small JSON file with a manifest, each of those experiments is something you can version, diff, and hand to someone else.
Now spend those bits where your work actually is
With iteration cheap, the interesting question comes back: which experts deserve the precision?
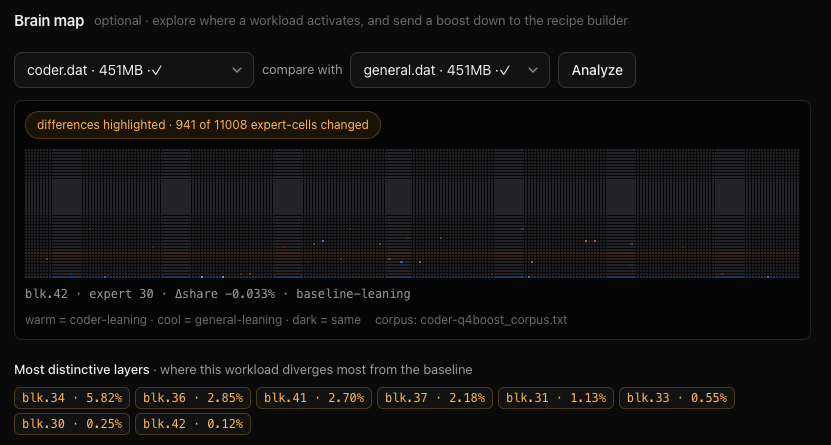
The trick is that importance matrix (imatrix): you run real examples through the model and watch which experts actually light up, and how hard. Those get the bits. You can build it four ways: from real benchmarks, from a corpus, from a raw list of prompts, or from live use. Serve the model, work normally, hit Ctrl-C. That last one records only aggregate per-expert statistics. No prompt text ever touches disk. The model learns where your work lives without keeping a record of your work. The imatrix steering this build came from real coding, not generic text, which is the whole point.
Then the fun part. I plot the imatrix as a brain map (43 layers × 256 experts) to see where a workload concentrates. Here’s the honest catch I hit: two domains’ maps look identical at a glance, because the router is trained to spread load evenly. Staring at two grids tells you nothing. The signal isn’t the heat, it’s the divergence. So I compare a domain against a baseline and surface the layers it uses differently:
forgequant paths coder.dat --contrast baseline.datThose domain-distinctive layers are the ones worth promoting from 2-bit to 4-bit. More fidelity exactly where coding actually lives, nowhere else. And thanks to the part above, trying that promotion costs five minutes, not an hour and a half.
Where this could go
Put the pieces together and the shape shows up.
Right now you calibrate once. But the loop wants to close: live use feeds the imatrix, --reuse cheaply rebuilds only the layers that drift, and a benchmark keeps the new version only if it actually wins. A model that quietly tunes itself to you, on hardware you own.
There’s a second payoff hiding in the SSD streaming. ds4 already keeps a cache of hot experts in RAM, and the brain map knows exactly which experts your domain leans on. Feed one into the other and the model that’s calibrated to your work could also be the one that streams fastest at it. Same map, quality and speed.
Further out: domain recipes you share like presets (a coding one, one tuned to your own repo, a medical one), and, since variants are cheap now, letting the machine search the bit allocation instead of me hand-picking it.
What this proves, and what it doesn’t
What this post claims is narrow and I want to keep it that way: the rebuild got faster and stayed byte-for-byte identical. That part I can prove, and did.
What it does not claim is that any of this calibration makes the model better at your work. That’s a separate question with a real trap in it: tune too hard on one slice and the model gets sharp there and soft everywhere else (there’s a mix knob to blend in general text for exactly this reason). A model can also feel smarter and benchmark worse, so the only way to settle it is a paired benchmark on the same questions, not vibes. I’ll do that properly in a follow-up, with benchy. Until then I’m only claiming the boring, checkable thing: making a variant went from eighty minutes to five, and the output is the same to the byte.
If you run local models and have opinions, please come tear it apart.
Built on ds4 / DwarfStar by antirez. Tools: forgequant (recipes and the brain map), my ds4 fork (--reuse, on-edge imatrix), benchy (the A/B harness, for the follow-up).